图论基础算法
树与图的存储
树是一种特殊的图,与图的存储方式相同。 对于无向图中的边ab,存储两条有向边a->b, b->a。 因此我们可以只考虑有向图的存储。
(1) 邻接矩阵:\(g[a][b]\) 存储边\(a->b\)
(2) 邻接表:
1 2 3 4 5 6 7 8 9 10 11 | |
拓扑排序
若一个由图中所有点构成的序列 \(A\) 满足:对于图中的每条边 \((x,y)\),\(x\) 在 \(A\) 中都出现在 \(y\) 之前,则称 \(A\) 是该图的一个拓扑序列。
代码模板
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | |
最短路
性质
对于边权为正的图,任意两个结点之间的最短路,不会经过重复的结点。
对于边权为正的图,任意两个结点之间的最短路,不会经过重复的边。
对于边权为正的图,任意两个结点之间的最短路,任意一条的结点数不会超过 \(n\),边数不会超过 \(n-1\)。
技巧
正权边图中求最长路可使用SPFA
经典Dijsktra可在全负权边图中跑最长路、全正权边图中跑最短路
记号
为了方便叙述,这里先给出下文将会用到的一些记号的含义。
- \(n\) 为图上点的数目,\(m\) 为图上边的数目;
- \(s\) 为最短路的源点;
- \(D(u)\) 为 \(s\) 点到 \(u\) 点的 实际 最短路长度;
- \(dis(u)\) 为 \(s\) 点到 \(u\) 点的 估计 最短路长度。任何时候都有 \(dis(u) \geq D(u)\)。特别地,当最短路算法终止时,应有 \(dis(u)=D(u)\)。
- \(w(u,v)\) 为 \((u,v)\) 这一条边的边权。
Dijkstra
将结点分成两个集合:已确定最短路长度的点集(记为 \(S\) 集合)的和未确定最短路长度的点集(记为 \(T\) 集合)。一开始所有的点都属于 \(T\) 集合。
初始化 \(dis(s)=0\),其他点的 \(dis\) 均为 \(+\infty\)。
然后重复这些操作:
- 从 \(T\) 集合中,选取一个最短路长度最小的结点,移到 \(S\) 集合中。
- 对那些刚刚被加入 \(S\) 集合的结点的所有出边执行松弛操作。
直到 \(T\) 集合为空,算法结束。
代码模板
\(O(n^2)\) 暴力跑稠密图
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | |
\(O(m\log m)\) 优先队列优化稀疏图
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | |
Bellman-Ford
对于边 \((u,v)\),松弛操作对应下面的式子:\(dis(v) = \min(dis(v), dis(u) + w(u, v))\)。
这么做的含义是显然的:我们尝试用 \(S \to u \to v\)(其中 \(S \to u\) 的路径取最短路)这条路径去更新 \(v\) 点最短路的长度,如果这条路径更优,就进行更新。
Bellman-Ford 算法所做的,就是不断尝试对图上每一条边进行松弛。我们每进行一轮循环,就对图上所有的边都尝试进行一次松弛操作,当一次循环中没有成功的松弛操作时,算法停止。
每次循环是 \(O(m)\) 的,那么最多会循环多少次呢?
在最短路存在的情况下,由于一次松弛操作会使最短路的边数至少 \(+1\),而最短路的边数最多为 \(n-1\),因此整个算法最多执行 \(n-1\) 轮松弛操作。故总时间复杂度为 \(O(nm)\)。
但还有一种情况,如果从 \(S\) 点出发,抵达一个负环时,松弛操作会无休止地进行下去。注意到前面的论证中已经说明了,对于最短路存在的图,松弛操作最多只会执行 \(n-1\) 轮,因此如果第 \(n\) 轮循环时仍然存在能松弛的边,说明从 \(S\) 点出发,能够抵达一个负环。
代码模板
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | |
SPFA: 优化版Bellman-Ford
很多时候我们并不需要那么多无用的松弛操作。
很显然,只有上一次被松弛的结点,所连接的边,才有可能引起下一次的松弛操作。
那么我们用队列来维护“哪些结点可能会引起松弛操作”,就能只访问必要的边了。
SPFA 也可以用于判断 \(s\) 点是否能抵达一个负环,只需记录最短路经过了多少条边,当经过了至少 \(n\) 条边时,说明 \(s\) 点可以抵达一个负环。
代码模板
求最短路
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 | |
判断是否存在负环
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 | |
栈版本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 | |
Floyd
我们定义一个数组 f[k][x][y],表示只允许经过结点 \(1\) 到 \(k\)(也就是说,在子图 \(V'={1, 2, \ldots, k}\) 中的路径,注意,\(x\) 与 \(y\) 不一定在这个子图中),结点 \(x\) 到结点 \(y\) 的最短路长度。
很显然,f[n][x][y] 就是结点 \(x\) 到结点 \(y\) 的最短路长度(因为 \(V'={1, 2, \ldots, n}\) 即为 \(V\) 本身,其表示的最短路径就是所求路径)。
接下来考虑如何求出 f 数组的值。
f[0][x][y]:\(x\) 与 \(y\) 的边权,或者 \(0\),或者 \(+\infty\)(f[0][x][y] 什么时候应该是 \(+\infty\)?当 \(x\) 与 \(y\) 间有直接相连的边的时候,为它们的边权;当 \(x = y\) 的时候为零,因为到本身的距离为零;当 \(x\) 与 \(y\) 没有直接相连的边的时候,为 \(+\infty\))。
f[k][x][y] = min(f[k-1][x][y], f[k-1][x][k]+f[k-1][k][y])(f[k-1][x][y],为不经过 \(k\) 点的最短路径,而 f[k-1][x][k]+f[k-1][k][y],为经过了 \(k\) 点的最短路)。
上面两行都显然是对的,所以说这个做法空间是 \(O(N^3)\),我们需要依次增加问题规模(\(k\) 从 \(1\) 到 \(n\)),判断任意两点在当前问题规模下的最短路。
因为第一维对结果无影响,我们可以发现数组的第一维是可以省略的,于是可以直接改成 f[x][y] = min(f[x][y], f[x][k]+f[k][y])。
证明第一维对结果无影响
我们注意到如果放在一个给定第一维 k 二维数组中,f[x][k] 与 f[k][y] 在某一行和某一列。而 f[x][y] 则是该行和该列的交叉点上的元素。
现在我们需要证明将 f[k][x][y] 直接在原地更改也不会更改它的结果:我们注意到 f[k][x][y] 的涵义是第一维为 k-1 这一行和这一列的所有元素的最小值,包含了 f[k-1][x][y],那么我在原地进行更改也不会改变最小值的值,因为如果将该三维矩阵压缩为二维,则所求结果 f[x][y] 一开始即为原 f[k-1][x][y] 的值,最后依然会成为该行和该列的最小值。
故可以压缩。
代码模板
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
最小生成树
给定一张边带权的无向图 \(G=(V,E)\),其中 \(V\) 表示图中点的集合,\(E\) 表示图中边的集合,\(n=|V|\),\(m=|E|\)。
由 \(V\) 中的全部 \(n\) 个顶点和 \(E\) 中 \(n−1\) 条边构成的无向连通子图被称为 \(G\) 的一棵生成树,其中边的权值之和最小的生成树被称为无向图 \(G\) 的最小生成树。
Prim
具体来说,每次要选择距离最小的一个结点,以及用新的边更新其他结点的距离。
其实跟 Dijkstra 算法一样,每次找到距离最小的一个点。
代码模板
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | |
Kruskal
Kruskal 算法是一种常见并且好写的最小生成树算法,由 Kruskal 发明。该算法的基本思想是从小到大加入边,是个贪心算法。
前置知识
实现
图示:
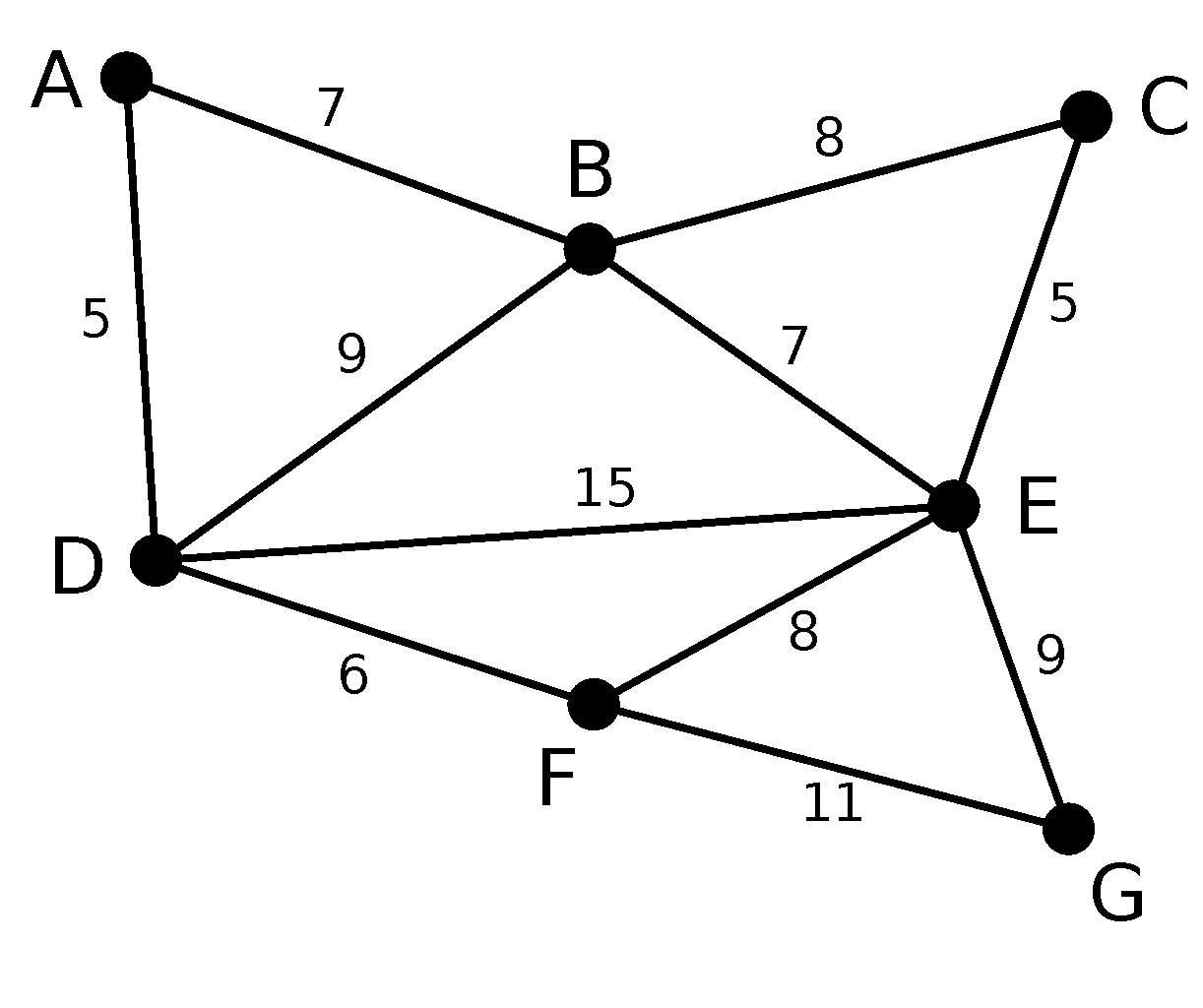
伪代码:
算法虽简单,但需要相应的数据结构来支持……具体来说,维护一个森林,查询两个结点是否在同一棵树中,连接两棵树。
抽象一点地说,维护一堆 集合,查询两个元素是否属于同一集合,合并两个集合。
其中,查询两点是否连通和连接两点可以使用并查集维护。
如果使用 \(O(m\log m)\) 的排序算法,并且使用 \(O(m\alpha(m, n))\) 或 \(O(m\log n)\) 的并查集,就可以得到时间复杂度为 \(O(m\log m)\) 的 Kruskal 算法。
证明
思路很简单,为了造出一棵最小生成树,我们从最小边权的边开始,按边权从小到大依次加入,如果某次加边产生了环,就扔掉这条边,直到加入了 \(n-1\) 条边,即形成了一棵树。
证明:使用归纳法,证明任何时候 K 算法选择的边集都被某棵 MST 所包含。
基础:对于算法刚开始时,显然成立(最小生成树存在)。
归纳:假设某时刻成立,当前边集为 \(F\),令 \(T\) 为这棵 MST,考虑下一条加入的边 \(e\)。
如果 \(e\) 属于 \(T\),那么成立。
否则,\(T+e\) 一定存在一个环,考虑这个环上不属于 \(F\) 的另一条边 \(f\)(一定只有一条)。
首先,\(f\) 的权值一定不会比 \(e\) 小,不然 \(f\) 会在 \(e\) 之前被选取。
然后,\(f\) 的权值一定不会比 \(e\) 大,不然 \(T+e-f\) 就是一棵比 \(T\) 还优的生成树了。
所以,\(T+e-f\) 包含了 \(F\),并且也是一棵最小生成树,归纳成立。
代码模板
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 | |
二分图
二分图,又称二部图,英文名叫 Bipartite graph。
二分图是什么?节点由两个集合组成,且两个集合内部没有边的图。
换言之,存在一种方案,将节点划分成满足以上性质的两个集合。

性质
-
如果两个集合中的点分别染成黑色和白色,可以发现二分图中的每一条边都一定是连接一个黑色点和一个白色点。
-
二分图不存在长度为奇数的环
因为每一条边都是从一个集合走到另一个集合,只有走偶数次才可能回到同一个集合。
染色法判断二分图
- 开始对任意一未染色的顶点染色。
- 判断其相邻的顶点中,若未染色则将其染上和相邻顶点不同的颜色。
- 若已经染色且颜色和相邻顶点的颜色相同则说明不是二分图,若颜色不同则继续判断。
代码模板
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | |
二分图的最大权匹配
二分图的匹配:给定一个二分图 \(G\),在 \(G\) 的一个子图 \(M\) 中,\(M\) 的边集 \(\{E\}\) 中的任意两条边都不依附于同一个顶点,则称 \(M\) 是一个匹配。
二分图的最大匹配:所有匹配中包含边数最多的一组匹配被称为二分图的最大匹配,其边数即为最大匹配数。
二分图的最大权匹配是指二分图中边权和最大的匹配。
Hungarian Algorithm(Kuhn-Munkres Algorithm)
匈牙利算法又称为 KM 算法,可以在 \(O(n^3)\) 时间内求出二分图的 最大权完美匹配。
考虑到二分图中两个集合中的点并不总是相同,为了能应用 KM 算法解决二分图的最大权匹配,需要先作如下处理:将两个集合中点数比较少的补点,使得两边点数相同,再将不存在的边权重设为 \(0\),这种情况下,问题就转换成求 最大权完美匹配问题,从而能应用 KM 算法求解。
可行顶标
给每个节点 \(i\) 分配一个权值 \(l(i)\),对于所有边 \((u,v)\) 满足 \(w(u,v) \leq l(u) + l(v)\)。
相等子图
在一组可行顶标下原图的生成子图,包含所有点但只包含满足 \(w(u,v) = l(u) + l(v)\) 的边 \((u,v)\)。
定理 1 : 对于某组可行顶标,如果其相等子图存在完美匹配,那么,该匹配就是原二分图的最大权完美匹配。
证明 1.
考虑原二分图任意一组完美匹配 \(M\),其边权和为
\(val(M) = \sum_{(u,v)\in M} {w(u,v)} \leq \sum_{(u,v)\in M} {l(u) + l(v)} \leq \sum_{i=1}^{n} l(i)\)
任意一组可行顶标的相等子图的完美匹配 \(M'\) 的边权和
\(val(M') = \sum_{(u,v)\in M} {l(u) + l(v)} = \sum_{i=1}^{n} l(i)\)
即任意一组完美匹配的边权和都不会大于 \(val(M')\),那个 \(M'\) 就是最大权匹配。
有了定理 1,我们的目标就是透过不断的调整可行顶标,使得相等子图是完美匹配。
因为两边点数相等,假设点数为 \(n\),\(lx(i)\) 表示左边第 \(i\) 个点的顶标,\(ly(i)\) 表示右边第 \(i\) 个点的顶标,\(w(u,v)\) 表示左边第 \(u\) 个点和右边第 \(v\) 个点之间的权重。
首先初始化一组可行顶标,例如
\(lx(i) = \max_{1\leq j\leq n} \{ w(i, j)\},\, ly(i) = 0\)
然后选一个未匹配点,如同最大匹配一样求增广路。找到增广路就增广,否则,会得到一个交错树。
令 \(S\),\(T\) 表示二分图左边右边在交错树中的点,\(S'\),\(T'\) 表示不在交错树中的点。
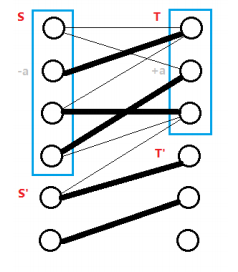
在相等子图中:
- \(S-T'\) 的边不存在,否则交错树会增长。
- \(S'-T\) 一定是非匹配边,否则他就属于 \(S\)。
假设给 \(S\) 中的顶标 \(-a\),给 \(T\) 中的顶标 \(+a\),可以发现
- \(S-T\) 边依然存在相等子图中。
- \(S'-T'\) 没变化。
- \(S-T'\) 中的 \(lx + ly\) 有所减少,可能加入相等子图。
- \(S'-T\) 中的 \(lx + ly\) 会增加,所以不可能加入相等子图。
所以这个 \(a\) 值的选择,显然得是 \(S-T'\) 当中最小的边权,
\(a = \min \{ lx(u) + ly(v) - w(u,v) | u\in{S} , v\in{T'} \}\)。
当一条新的边 \((u,v)\) 加入相等子图后有两种情况
- \(v\) 是未匹配点,则找到增广路
- \(v\) 和 \(S'\) 中的点已经匹配
这样至多修改 \(n\) 次顶标后,就可以找到增广路。
每次修改顶标的时候,交错树中的边不会离开相等子图,那么我们直接维护这棵树。
我们对 \(T\) 中的每个点 \(v\) 维护
\(slack(v) = \min \{ lx(u) + ly(v) - w(u,v) | u\in{S} \}\)。
所以可以在 \(O(n)\) 算出顶标修改值 \(a\)
\(a = \min \{ slack(v) | v\in{T'} \}\)
交错树新增一个点进入 \(S\) 的时候需要 \(O(n)\) 更新 \(slack(v)\)。修改顶标需要 \(O(n)\) 给每个 \(slack(v)\) 减去 \(a\)。只要交错树找到一个未匹配点,就找到增广路。
一开始枚举 \(n\) 个点找增广路,为了找增广路需要延伸 \(n\) 次交错树,每次延伸需要 \(n\) 次维护,共 \(O(n^3)\)。
代码模板
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | |