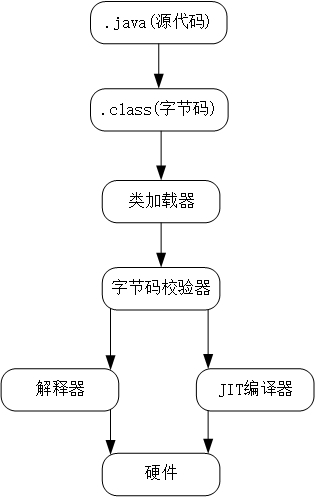
这个时候我们就需要更加高效的方式来运行Java程序,随着后面的发展,现在大多数的主流的JVM都包含即时编译器。JVM会根据当前代码的进行判断,当虚拟机发现某个方法或代码块的运行特别频繁时,就会把这些代码认定为“热点代码”。为了提高热点代码的执行效率,在运行时,虚拟机将会把这些代码编译成与本地平台相关的机器码,并进行各种层次的优化,完成这个任务的编译器称为即时编译器(Just In Time Compiler)
Welcome to Ubuntu 20.04.3 LTS (GNU/Linux 5.4.0-96-generic x86_64)
* Documentation: https://help.ubuntu.com
* Management: https://landscape.canonical.com
* Support: https://ubuntu.com/advantage
System information as of Sat 29 Jan 202210:33:03 AM UTC
System load: 0.08 Processes: 156
Usage of /: 5.5% of 108.05GB Users logged in: 0
Memory usage: 5% IPv4 address for enp2s0: 192.168.10.66
Swap usage: 0% IPv4 address for enp2s0: 192.168.10.75
Temperature: 32.0 C
37 updates can be applied immediately.
To see these additional updates run: apt list --upgradable
Last login: Sat Jan 2910:27:06 2022
nagocoler@ubuntu-server:~$
nagocoler@ubuntu-server:~$ gcc --version
gcc (Ubuntu 4.8.5-4ubuntu2)4.8.5
Copyright (C)2015 Free Software Foundation, Inc.
This is free software; see the sourcefor copying conditions. There is NO
warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
nagocoler@ubuntu-server:~$ g++ --version
g++ (Ubuntu 4.8.5-4ubuntu2)4.8.5
Copyright (C)2015 Free Software Foundation, Inc.
This is free software; see the sourcefor copying conditions. There is NO
warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
...#ifdef HAVE_CONFIG_H#include<config.h>#endif#define __alloca alloca <- 添加这一句/* Enable GNU extensions ...
接着进行配置并完成编译和安装:
12
bash configure
sudo make install
安装完成后,将make已经变成3.81版本了:
123456
nagocoler@ubuntu-server:~/make-3.81$ make -verison
GNU Make 3.81
Copyright (C)2006 Free Software Foundation, Inc.
This is free software; see the sourcefor copying conditions.
There is NO warranty; not even for MERCHANTABILITY or FITNESS FOR A
PARTICULAR PURPOSE.
Configuration summary:
* Debug level: slowdebug
* JDK variant: normal
* JVM variants: server
* OpenJDK target: OS: linux, CPU architecture: x86, address length: 64
Tools summary:
* Boot JDK: openjdk version "1.8.0_312" OpenJDK Runtime Environment (build 1.8.0_312-8u312-b07-0ubuntu1~20.04-b07) OpenJDK 64-Bit Server VM (build 25.312-b07, mixed mode) (at /usr/lib/jvm/java-8-openjdk-amd64)
* C Compiler: gcc-4.8 (Ubuntu 4.8.5-4ubuntu2) version 4.8.5 (at /usr/bin/gcc-4.8)
* C++ Compiler: g++-4.8 (Ubuntu 4.8.5-4ubuntu2) version 4.8.5 (at /usr/bin/g++-4.8)
Build performance summary:
* Cores to use: 3
* Memory limit: 3824 MB
* ccache status: not installed (consider installing)
WARNING: The result of this configuration has overridden an older
configuration. You *should* run 'make clean' to make sure you get a
proper build. Failure to do so might result in strange build problems.
/home/nagocoler/jdk-jdk8-b120/build/linux-x86_64-normal-server-slowdebug/jdk/bin/java -version
openjdk version "1.8.0-internal-debug"
OpenJDK Runtime Environment (build 1.8.0-internal-debug-nagocoler_2022_01_29_11_36-b00)
OpenJDK 64-Bit Server VM (build 25.0-b62-debug, mixed mode)
Process finished with exit code 0
nagocoler@ubuntu-server:~$ cd JavaHelloWorld/
nagocoler@ubuntu-server:~/JavaHelloWorld$ vim Main.java
nagocoler@ubuntu-server:~/JavaHelloWorld$ javac Main.java
nagocoler@ubuntu-server:~/JavaHelloWorld$ ls
Main.class Main.java
点击运行,成功得到结果:
1234
/home/nagocoler/jdk-jdk8-b120/build/linux-x86_64-normal-server-slowdebug/jdk/bin/java Main
Hello World!
Process finished with exit code 0
intJLI_Launch(intargc,char**argv,/* main argc, argc */intjargc,constchar**jargv,/* java args */intappclassc,constchar**appclassv,/* app classpath */constchar*fullversion,/* full version defined */constchar*dotversion,/* dot version defined */constchar*pname,/* program name */constchar*lname,/* launcher name */jbooleanjavaargs,/* JAVA_ARGS */jbooleancpwildcard,/* classpath wildcard */jbooleanjavaw,/* windows-only javaw */jintergo_class/* ergnomics policy */);
InitLauncher(javaw);DumpState();if(JLI_IsTraceLauncher()){inti;printf("Command line args:\n");for(i=0;i<argc;i++){printf("argv[%d] = %s\n",i,argv[i]);}AddOption("-Dsun.java.launcher.diag=true",NULL);}
接着就是选择一个合适的JRE版本:
1 2 3 4 5 6 7 8 9101112131415161718
/* * Make sure the specified version of the JRE is running. * * There are three things to note about the SelectVersion() routine: * 1) If the version running isn't correct, this routine doesn't * return (either the correct version has been exec'd or an error * was issued). * 2) Argc and Argv in this scope are *not* altered by this routine. * It is the responsibility of subsequent code to ignore the * arguments handled by this routine. * 3) As a side-effect, the variable "main_class" is guaranteed to * be set (if it should ever be set). This isn't exactly the * poster child for structured programming, but it is a small * price to pay for not processing a jar file operand twice. * (Note: This side effect has been disabled. See comment on * bugid 5030265 below.) */SelectVersion(argc,argv,&main_class);
jbooleanLoadJavaVM(constchar*jvmpath,InvocationFunctions*ifn){Dl_infodlinfo;void*libjvm;JLI_TraceLauncher("JVM path is %s\n",jvmpath);libjvm=dlopen(jvmpath,RTLD_NOW+RTLD_GLOBAL);if(libjvm==NULL){JLI_ReportErrorMessage(DLL_ERROR1,__LINE__);JLI_ReportErrorMessage(DLL_ERROR2,jvmpath,dlerror());returnJNI_FALSE;}ifn->CreateJavaVM=(CreateJavaVM_t)dlsym(libjvm,"JNI_CreateJavaVM");if(ifn->CreateJavaVM==NULL){JLI_ReportErrorMessage(DLL_ERROR2,jvmpath,dlerror());returnJNI_FALSE;}ifn->GetDefaultJavaVMInitArgs=(GetDefaultJavaVMInitArgs_t)dlsym(libjvm,"JNI_GetDefaultJavaVMInitArgs");if(ifn->GetDefaultJavaVMInitArgs==NULL){JLI_ReportErrorMessage(DLL_ERROR2,jvmpath,dlerror());returnJNI_FALSE;}ifn->GetCreatedJavaVMs=(GetCreatedJavaVMs_t)dlsym(libjvm,"JNI_GetCreatedJavaVMs");if(ifn->GetCreatedJavaVMs==NULL){JLI_ReportErrorMessage(DLL_ERROR2,jvmpath,dlerror());returnJNI_FALSE;}returnJNI_TRUE;}
intContinueInNewThread(InvocationFunctions*ifn,jlongthreadStackSize,intargc,char**argv,intmode,char*what,intret){...rslt=ContinueInNewThread0(JavaMain,threadStackSize,(void*)&args);/* If the caller has deemed there is an error we * simply return that, otherwise we return the value of * the callee */return(ret!=0)?ret:rslt;}}
intContinueInNewThread0(int(JNICALL*continuation)(void*),jlongstack_size,void*args){intrslt;pthread_ttid;pthread_attr_tattr;pthread_attr_init(&attr);pthread_attr_setdetachstate(&attr,PTHREAD_CREATE_JOINABLE);if(stack_size>0){pthread_attr_setstacksize(&attr,stack_size);}if(pthread_create(&tid,&attr,(void*(*)(void*))continuation,(void*)args)==0){void*tmp;pthread_join(tid,&tmp);rslt=(int)tmp;}else{/* * Continue execution in current thread if for some reason (e.g. out of * memory/LWP) a new thread can't be created. This will likely fail * later in continuation as JNI_CreateJavaVM needs to create quite a * few new threads, anyway, just give it a try.. */rslt=continuation(args);}pthread_attr_destroy(&attr);returnrslt;}
最后实际上是在新的线程中执行JavaMain函数,最后我们再来看看此函数里面做了什么事情:
123456
/* Initialize the virtual machine */start=CounterGet();if(!InitializeJVM(&vm,&env,&ifn)){JLI_ReportErrorMessage(JVM_ERROR1);exit(1);}
/* * Get the application's main class. * * See bugid 5030265. The Main-Class name has already been parsed * from the manifest, but not parsed properly for UTF-8 support. * Hence the code here ignores the value previously extracted and * uses the pre-existing code to reextract the value. This is * possibly an end of release cycle expedient. However, it has * also been discovered that passing some character sets through * the environment has "strange" behavior on some variants of * Windows. Hence, maybe the manifest parsing code local to the * launcher should never be enhanced. * * Hence, future work should either: * 1) Correct the local parsing code and verify that the * Main-Class attribute gets properly passed through * all environments, * 2) Remove the vestages of maintaining main_class through * the environment (and remove these comments). * * This method also correctly handles launching existing JavaFX * applications that may or may not have a Main-Class manifest entry. */mainClass=LoadMainClass(env,mode,what);
某些没有主方法的Java程序比如JavaFX应用,会获取ApplicationMainClass:
1234567
/* * In some cases when launching an application that needs a helper, e.g., a * JavaFX application with no main method, the mainClass will not be the * applications own main class but rather a helper class. To keep things * consistent in the UI we need to track and report the application main class. */appClass=GetApplicationClass(env);
初始化完成:
12345678
/* * PostJVMInit uses the class name as the application name for GUI purposes, * for example, on OSX this sets the application name in the menu bar for * both SWT and JavaFX. So we'll pass the actual application class here * instead of mainClass as that may be a launcher or helper class instead * of the application class. */PostJVMInit(env,appClass,vm);
接着就是获取主类中的主方法:
12345678
/* * The LoadMainClass not only loads the main class, it will also ensure * that the main method's signature is correct, therefore further checking * is not required. The main method is invoked here so that extraneous java * stacks are not in the application stack trace. */mainID=(*env)->GetStaticMethodID(env,mainClass,"main","([Ljava/lang/String;)V");
/* Invoke main method. */(*env)->CallStaticVoidMethod(env,mainClass,mainID,mainArgs);
调用后,我们的Java程序就开飞速运行起来,直到走到主方法的最后一行返回:
123456
/* * The launcher's exit code (in the absence of calls to * System.exit) will be non-zero if main threw an exception. */ret=(*env)->ExceptionOccurred(env)==NULL?0:1;LEAVE();
/* DO NOT EDIT THIS FILE - it is machine generated */#include<jni.h>/* Header for class com_test_Main */#ifndef _Included_com_test_Main#define _Included_com_test_Main#ifdef __cplusplusextern"C"{#endif/* * Class: com_test_Main * Method: sum * Signature: (II)V */JNIEXPORTvoidJNICALLJava_com_test_Main_sum(JNIEnv*,jclass,jint,jint);#ifdef __cplusplus}#endif#endif